
YOLO
YOLO
模型评价指标
IOU(输出框与真实框的交集/并集):

TP: T表示True,P表示Positive。True和False表示模型判断的对错,Positive和Negative表示该样本被判断为什么。那么如果一个样被我们判定为好的(Positive),而且我们判断对了,那么即为一个TP
FP: 同理,FP即为被我们判断为好的(Positive),但是我们判断错了(即它是错误的样本),即为FP
TN: 被模型识别为坏的(Negative),我们判断对了(它确实是坏的)
FN: 被模型识别为坏的(Negative),但我们判断错了(它实际上是对的)
由此,定义:
$$
Precision\ =\ \frac{TP}{TP\ +\ FP}
$$
$$
Recall\ =\ \frac{TP}{TP\ +\ FN}
$$
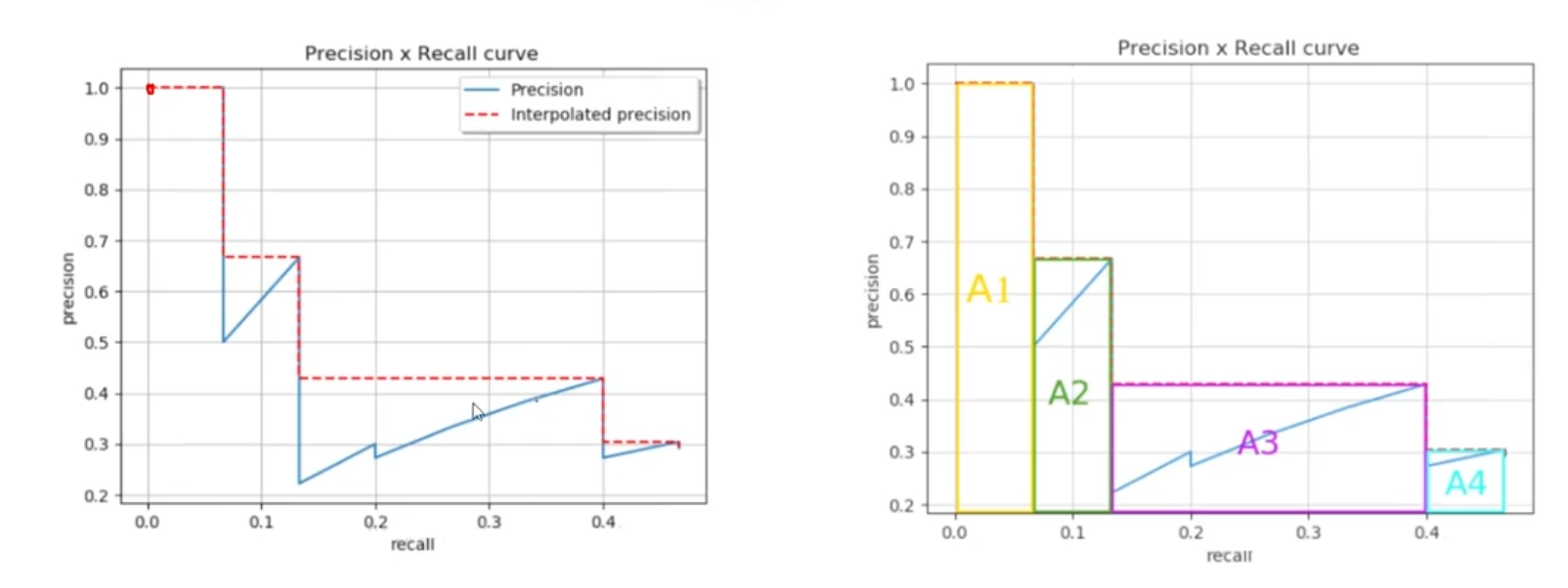
在不同的置信度下,计算对应的Precision和Recall,做出图像,计算如下右图的阴影面积
YOLO-V1
You Only Look Once !
是一个经典的one-stage方法,它将检测问题转化为回归问题,一个CNN搞定问题。
网络架构
YOLO-v1指定输入图片大小为448*448*3。输入图像经过一系列卷积层,变成7*7*1024的大小。展成一维后,经过两层全连接层,变成1470*1,将其reshape成7*7*30的大小。
将7*7视作二维图像按7*7分后的样子,每个格子有30个值。我们将每个格子看作中心格子,有两种预选框的形状(提前定好的),这三十个值的前10个值我们视作两组(x, y, w, h, c),c为置信度,对应两种预选框的参数。后面的20个值为20个分类的概率值。
损失函数
YOLO-V2(细节微调)
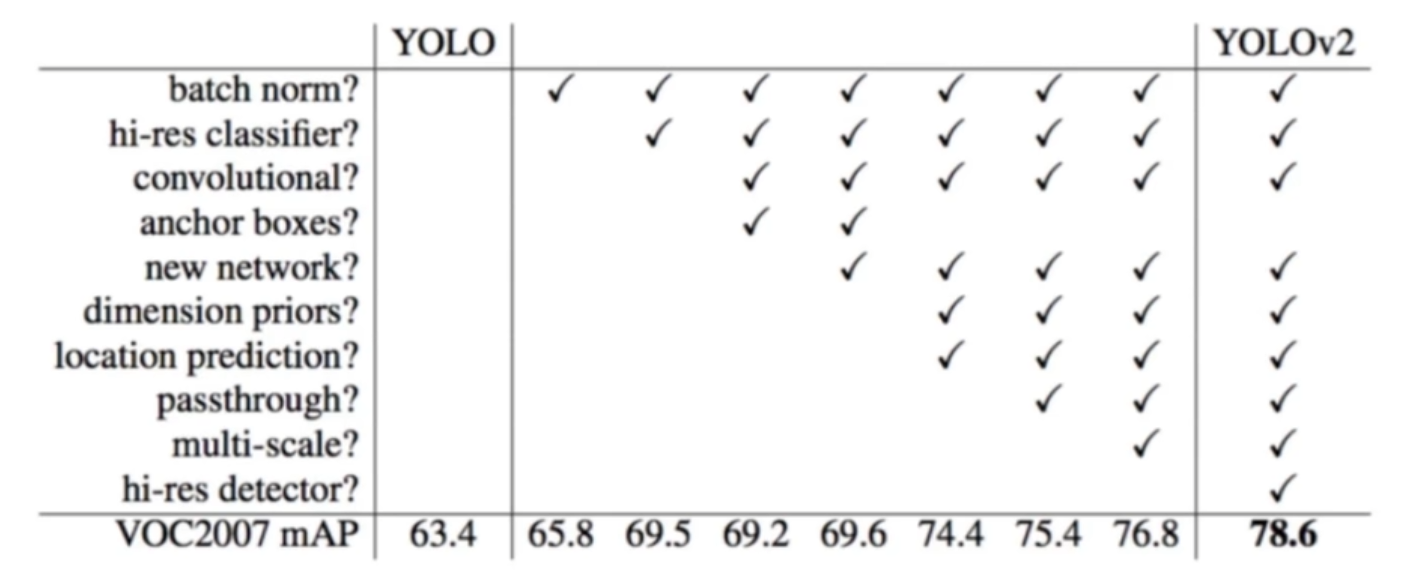
Batch Norm
- V2舍弃Dropout,卷积后全部加入Batch Normalization
- 网络的每一层的输入都做了归一化,收敛相对更容易
- 经过Batch Normalization处理后的网络会提升2%的mAP
- 从现在的角度来看,Batch Normalization已经成网络必备处理
更大的分辨率
- V1训练时用的是224*224,测试时使用448*448
- 因此这种不同可能导致模型水土不服,V2训练时额外又加入了10次448*448的微调
- 使用高分辨率分类器后,YOLO V2的mAP提升了约4%
网络结构
- 采用DarkNet,实际输入为416*416(这样经过降采样,416正好被32整除)
- 没有FC层,5次降采样(变为原来的32分之一,原图像变为13*13)
- 1*1卷积节省了很多参数
先验框
- 先验比例不一定适合数据集
- 聚类提取先验框
坐标换算

- 最后还要再✖32,还原到原来的坐标
YOLO v5
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Ando's blog!
相关推荐

