
图着色寄存器分配算法
图着色寄存器分配算法
背景架构概述
这里先阐明我架构中的几个概念:
虚拟寄存器:在生成后端代码时暂用的寄存器,寄存器分配的过程中会将虚拟寄存器逐一替换为物理寄存器
基本块:后端代码的每个函数中包含着若干基本块,每个基本块有若干指令构成且最后一条一定是跳转或返回指令
生命周期:一个寄存器的生命周期从该寄存器第一次被定义开始,一直到该寄存器中的值最后一次被使用
临时寄存器:没有被提前染色(即不属于abi约定好功能的寄存器),也没有被算法处理过的寄存器。
原理概述
将每个虚拟寄存器视作一个点,若两个虚拟寄存器的生命周期有重合的地方,即为它们连一条边,由此构建一个图。我们为图上的每个点染色,要求是一条边上的两个点不能为相同的颜色,且尽量用较少的颜色去染色(其实就是用较少的寄存器)。这就是图着色法对寄存器分配问题的抽象。
这是一个NP完全问题,我们找到最优解会花费较长时间,因此我们通常采用的是一种启发式算法。
算法流程概述
算法大致分为以下五个阶段:build, coalesce, simplify, spill, select。
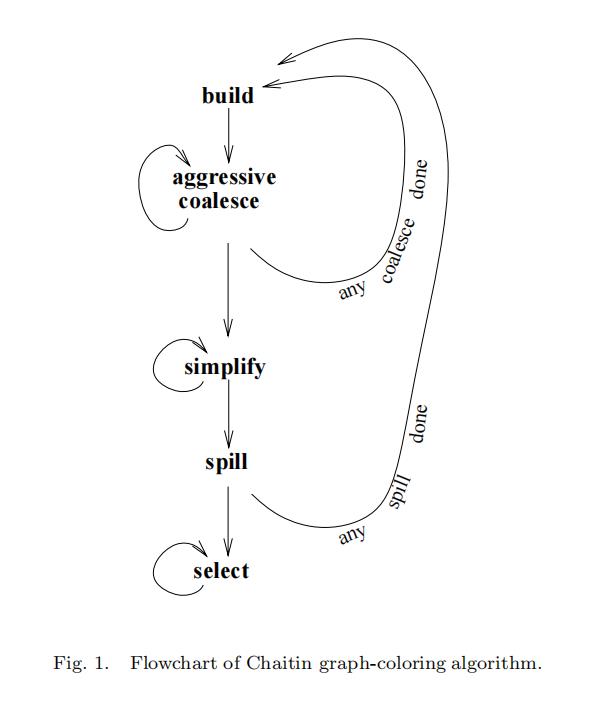
build: 构建香蕉相交图(interference graph)。我们首先通过活跃变量分析对每个基本块中的寄存器的生命周期进行分析,然后以此为依据构建相交图。由上图我们可以看到,几乎后续的每一步做完了都要回来build一下。
coalesce: 移除没用的move指令。当move指令中的rd寄存器和rs寄存器在图中不相邻时,我们可以令rd和rs用一个寄存器。当我们完成coalesce之后,我们要重新build相交图,从而可能会有新的可移除的move指令。一直重复build-coalesce的过程,直到没有可移除的move指令。(这里建议手动画图思考一下合并的过程,一会要着重分析合并)
simplify: 对图进行简化。这里我们采用一个简单的启发式算法:假设图G中有一个点m,它的邻边小于K(K是后端可用寄存器的数量),我们可以把点m压入一个栈,并删除所有与m相邻的边,从而得到图G’。若图G’仍存在这样的点m,重复simplify过程,否则进入spill过程。
spill: 处理寄存器溢出的情况。当所有点的邻边都>K时,我们只好选择一个节点作为溢出节点,将它放到内存。显然,我们将该节点放到内存后,它就不会再影响其他的寄存器分配。因此我们应当移除该节点,并在源后端程序中将含有该寄存器的代码重写为lw和sw,并重新执行build等步骤。我们持续这个过程直至没有节点溢出。
select: 对图进行染色。我们从一个空图开始,每次取出栈顶的一个点进行染色。由上述算法我们可知,到这里我们一定可以用<=K中颜色染完这个图。我们只需要在每次新取出一个点的时候,为它染上非相邻节点的颜色即可。
coalesce分析
不能无脑合并!
coalesce的过程有点特殊,我们需要分析一下。虽然移除move指令看着很爽,但是我们却不能无脑移除所有不相交的。显然,当我们移除一条move指令,将两个寄存器合二为一的时候,这个寄存器的生命周期会变长,在图上就会体现为产生更多边,图更加密集,这也就加剧了出现不可解图的可能性。这里解释一下什么样的图是不可解的。我们在最开始会为一些寄存器预着色,即precolored。哪些寄存器呢?是那些abi约定好的寄存器,比如a0,a1,a2,a3等用于传递参数,v0,v1等用于返回函数值,sp用于压栈等等,这些寄存器有特定的用处,最开始要被预着色,而且这些被预着色的寄存器也是不能被spill出去的。那么我们如果采取无脑合并的策略,就会有可能将所有的寄存器和预着色的寄存器合并,导致所有寄存器都被预着色,而此时我们没有办法spill,即出现了不可解图。
一个保守的策略
首先我们新声明一个概念:significant degree,下文称为重要节点。一个重要节点表示它有>=K个邻边。一个保守的策略就是只有当合并之后的节点相邻的重要节点小于K时才合并。证明很简单:我们在simplify阶段会把所有不重要的节点都放到栈里,假设合并出了一个重要节点,由于上述条件的约束,合并之后的节点此时只有<K个邻居,因此不是重要节点,即假设不成立,合并之后的节点一定可以消到一个不重要节点,因此此次合并不会使一个可解图变为不可解图。但是这个策略并不是最优的,因为即使我们合并出的节点的邻居中有>=k个重要节点,图也不一定不可解(因为可能有两个或多个重要节点为一个颜色,那么我们就可以为其染色)。
有偏着色算法
于是就又有科学家提出了新算法。这个算法作用于染色阶段。当我们染色的时候,例如给move指令中的临时寄存器X染色时,我们观察move指令中另一个寄存器Y的情况。如果Y已经染色,那么我们尝试为X也染上相同的颜色。如果Y没有被染色,那么我们为X尽量避免选择Y邻居的颜色,以提高一会染色到Y时,Y和X能拥有相同颜色的可能性。
再物质化
注意到将含有常量值的变量spill掉,效率是非常高的。首先我们不需要store,并且每次使用都会重新计算或者重新赋值。因此这个优化可以和常数传播结合,形成一个针对存有常数的变量的spill策略。
同时,这也启发我们可以使用这样的合并策略:当我们知道a和b为常数时,我们应该不顾一切的合并a和b。因为即使发生了溢出,溢出的成本也很低。
迭代寄存器合并算法(核心流程)
综上,我们将上文提到的算法进行改良,有以下流程:
- build: 我们在build相关图的时候,注意标记变量是否可移动
- simplify: 将低度变量移出图
- coalesce: 进行保守算法的合并,可合并的合并后可能会产生新的可simplify的低度变量,一直进行simplify和coalesce,直到图中全是重要节点或者移动变量
- freeze: 我们将图中的一个低度节点freeze,这意味着我们放弃了合并与其有关的move指令,并视作该节点为非移动变量,接下来再重复simplify-coalesce循环。
- select: 染色。与之前一样,但不采用有偏着色算法。虽然考虑到使用有偏着色可能能消除更多冻结的move指令。
乐观着色
乐观着色:我们在压栈的时候,当发现图中没有<K度的节点的时候,你先别急,我们先不把它当作spill,它只是一个潜在的spill。等到染色的时候,发现没有颜色可以用了,这才是真spill。此时我们把它spill掉。

