
selenium入门
Selenium入门
原理&安装
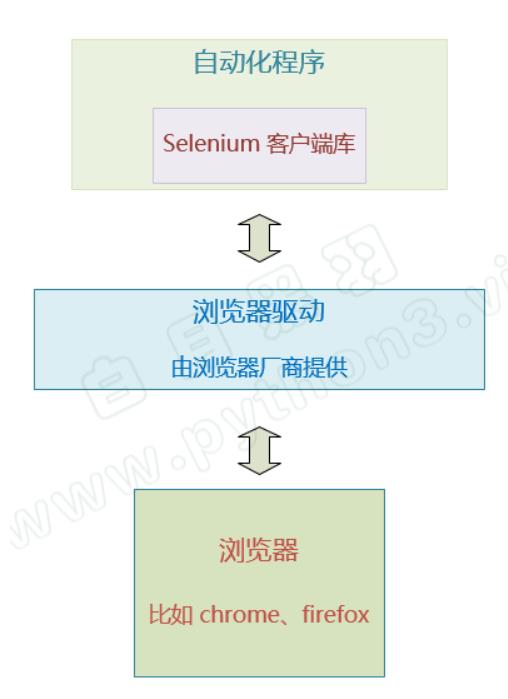
我们写代码模拟用户操作时,调用Selenium里的接口,Selenium将对应的请求发送给浏览器驱动,浏览器驱动再将请求转化后发送给浏览器
浏览器驱动 也是一个独立的程序,是由浏览器厂商提供的,不同的浏览器需要不同的浏览器驱动。比如 Chrome浏览器和火狐浏览器有各自不同的驱动程序。
安装只需执行下述命令:
1 | pip install selenium |
同时我们还要安装浏览器驱动
https://chromedriver.storage.googleapis.com/index.html
这里尽量选择与浏览器版本相近的驱动
Tip: Chrome设置里关于Chrome可查看Chrome版本
示例1
1 | from selenium import webdriver //import Selenium中的webdriver |
wd.quit()可以关闭浏览器窗口
省略浏览器驱动路径
将驱动路径加入环境变量Path中,注意这里的路径不需要有chromedriver.exe,只要有前面的路径即可。
原代码可改为
1 | wd = webdriver.Chrome() |
选择元素的基本方法
首先添加一行代码:
1 | from selenium.webdriver.common.by import By |
1.根据id属性
1 | element = wd.find_element(By.ID, 'kw') |
2.根据class属性
1 | elements = wd.find_elements(By.CLASS_NAME, 'animal') |
具有多个class属性的元素第二个参数不能填入多个属性名,只能通过一个属性名查找
3.根据tag属性
1 | elements = wd.find_elements(By.TAG_NAME, 'div') |
使用
find_elements选择的是符合条件的所有元素, 如果没有符合条件的元素,返回空列表使用
find_element选择的是符合条件的第一个元素, 如果没有符合条件的元素,抛出 NoSuchElementException 异常
4.通过WebElement对象选择元素
1 | element = wd.find_element(By.ID,'container') |
可以理解为一层层限定范围
等待界面元素出现
由于我们浏览器获取服务器端数据需要一定时间延迟,所以有可能会发生我们的代码执行比浏览器获取数据快的情况,这时我们便无法正确得到选择的元素,对此,Selenium提供了一个合理的解决方案:
Selenium 的 Webdriver 对象 有个方法叫 implicitly_wait ,可以称之为 隐式等待 ,或者 全局等待 。该方法接受一个参数, 用来指定最大等待时长。如果我们加入如下代码:
1 | wd.implicitly_wait(10) |
那么后续所有的 find_element 或者 find_elements 之类的方法调用都会采用如下策略:
如果找不到元素,每隔半秒钟再去界面上查看一次,直到找到该元素,或者过了10秒最大时长。
操控元素
点击元素:
1 | wd.click() |
输入框:
1 | element.send_keys('xxx') |
清除输入框已有的值:
1 | element.clear() |
获取元素文本内容:
1 | element = wd.find_element(By.ID, 'xxx') |
获取元素属性:
1 | element = wd.find_element(By.ID, 'xxx') |
获取元素内部的HTML:
1 | element.get_attribute('innerHTML') |
获取整个元素对应的HTML:
1 | element.get_attribute('outerHTML') |
获取输入框里的文字:
1 | element = wd.find_element(By.ID, "input1") |
CSS表达式
根据id选择:
1 | element = wd.find_element(By.CSS_SELECTOR, '#searchtext') |
根据tag选择:
1 | elements = wd.find_elements(By.CSS_SELECTOR, 'div') |
根据class选择:
1 | elements = wd.find_elements(By.CSS_SELECTOR, '.animal') |
选择子元素:
1 | elements = wd.find_elements(By.CSS_SELECTOR, '#app .demo div') |
根据属性选择:
1 | element = wd.find_element(By.CSS_SELECTOR, 'a[href="http://www.miitbeian.gov.cn"]') |
组选择:
1 | element = wd.find_element(By.CSS_SELECTOR, 'div, #test') |
父元素的第n个子节点:
1 | element = wd.find_element(By.CSS_SELECTOR, 'span:nth-child(2)') |
父元素的倒数第n个子节点:
1 | element = wd.find_element(By.CSS_SELECTOR, 'span:nth-last-child(2)') |
父元素的第n个某类型子节点:
1 | element = wd.find_element(By.CSS_SELECTOR, 'div span:nth-of-type(2)') |
父元素的倒数第几个某类型的子节点
1 | element = wd.find_element(By.CSS_SELECTOR, 'div span:nth-last-of-child(2)') |
奇数节点和偶数节点:
1 | element = wd.find_element(By.CSS_SELECTOR, 'span:nth-child(odd)') |
相邻兄弟节点:
1 | element = wd.find_element(By.CSS_SELECTOR, 'h1 + span') |
后续所有兄弟节点:
1 | element = wd.find_element(By.CSS_SELECTOR, 'h1 ~ span') |

